对抗攻击的介绍、分类等… (Photo by Alex Chumak on Unsplash )
为什么要有对抗攻击
现实生活中可能会有恶意的攻击,为了让训练的模型能够使用于现实生活中,需要增强模型对攻击的鲁棒性,便需要研究模型的攻击和防御
攻击和防御,先研究攻击更简单
如何做到攻击,攻击要做到什么?
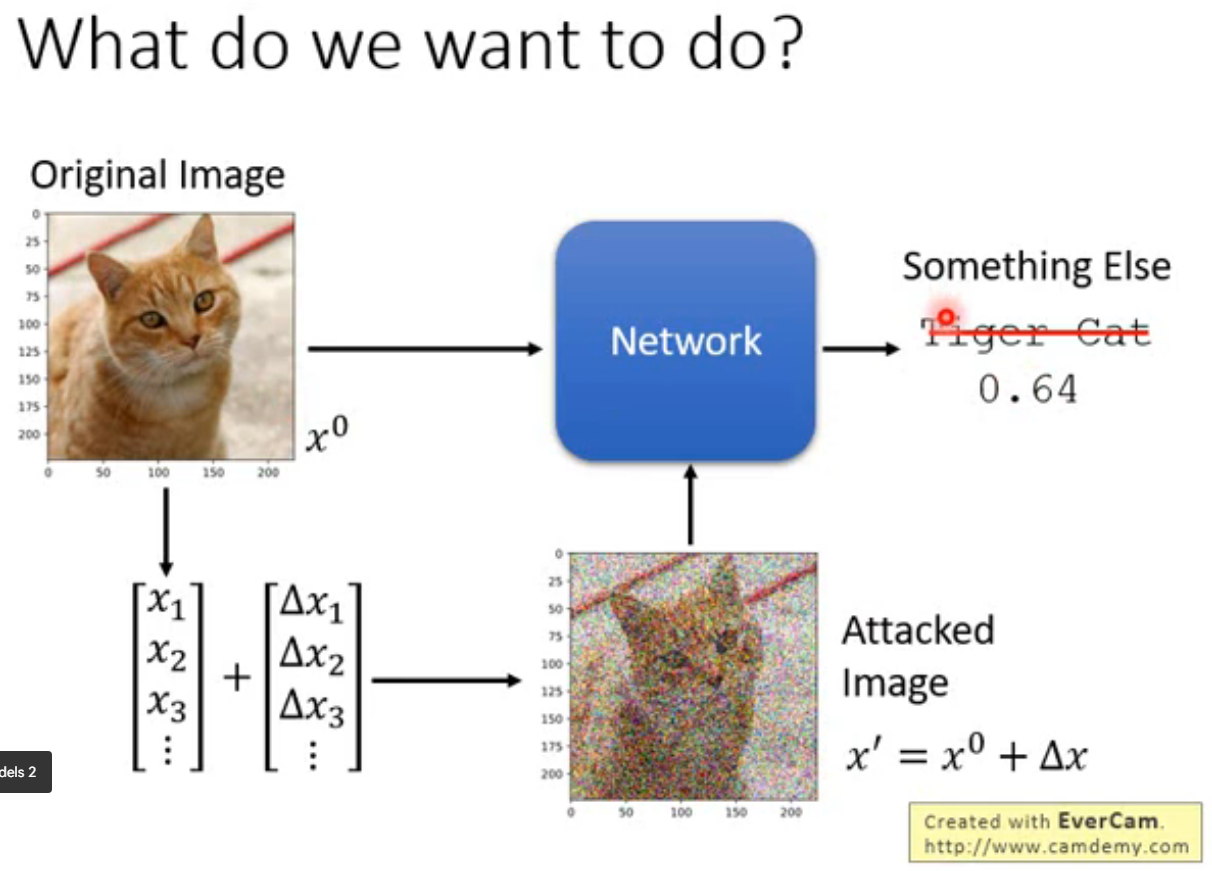
在原始图像上添加噪声,经过网络模型后会得到完全不同的、有违事实的结果
Loss Function for Attack
攻击依据目的可以分为:
- Non-targeted Attack:只要求攻击后输出结果错误
- Targeted Attack:要求攻击后输出结果与一个特定结果相似
训练攻击样本:
两种攻击的样本都应该满足添加噪声后,与原图差异肉眼不可见的Constraint:
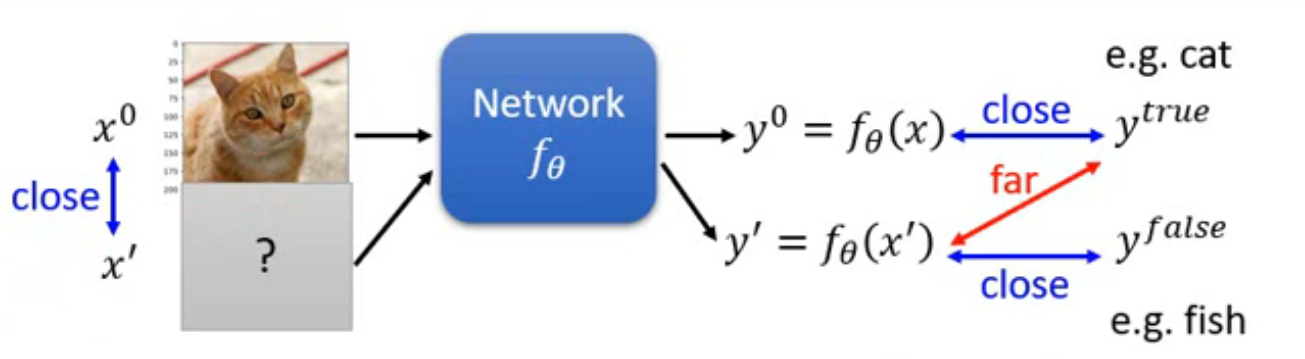
对于Non-targeted Attack:
训练时的 Loss 函数可以表示为:
Constraint:
即在网络参数 不变的情况下,图像输出 与真实值 差距越大越好,同时,输入图像 与原始图像 越接近越好
对于Targeted Attack:
训练时的 Loss 函数可以表示为:
Constraint:
即在网络参数 不变的情况下,图像输出 与真实值 差距越大越好,与目标错误图像 越接近越好,同时,输入图像 与原始图像 越接近越好
Constraint
Constraint: 中,距离函数 的实现有多种方式,设$$\Delta x = x^{\prime} - x ^0 = \left[ \begin{matrix} x^{\prime}_1\newline x^{\prime}_2\newline x^{\prime}_3\newline \vdots \end{matrix}\right] - \left[ \begin{matrix} x^0_1\newline x^0_2\newline x^0_3\newline \vdots \end{matrix}\right] = \left[ \begin{matrix} \Delta x_1\newline \Delta x_2\newline \Delta x_3\newline \vdots \end{matrix}\right]$$
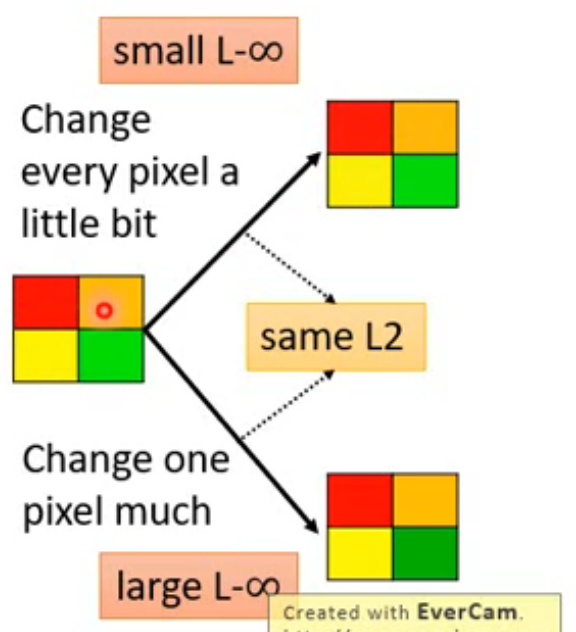
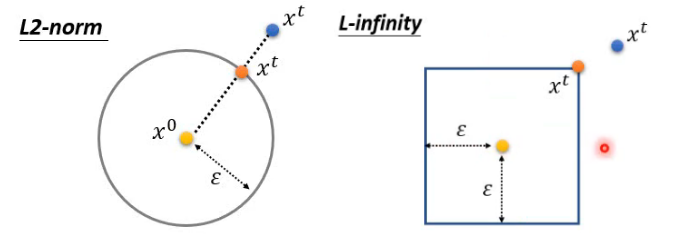
- L2-norm:
- L-infinity:
在保持 L2 相同时,可以发现 L-∞ 的变化更能反应人类对图像间的差异,L-∞ 更适合用来处理图像攻击(见仁见智)
如何攻击
与训练模型时类似,训练模型时是改变模型参数 ,训练攻击样本时是改变输入的样本 ,训练时应该遵循:
训练时使用梯度下降Gradient Descent方法,与训练模型参数时不同,训练攻击样本时需要实时检查 是否超出Constraint,超出需要将 做一个修正

修正函数也比较简单,如果 超出范围,只需要在允许范围内找到一个和 距离最短的点作为 的修正值即可
攻击的一个 Example
使用模型为 ,迭代训练 50 epoch,原始输出为 Tiger cat (置信度为 0.64),攻击后输出为 Star Fish (置信度为 1.00),但是训练出来的攻击样本与原图的差距肉眼不可见

将噪声放大 50 倍后如图:

为什么会有这样的攻击效果
向原始输入图像加入随机噪声,得到的输出也会变化,但是不会很离谱

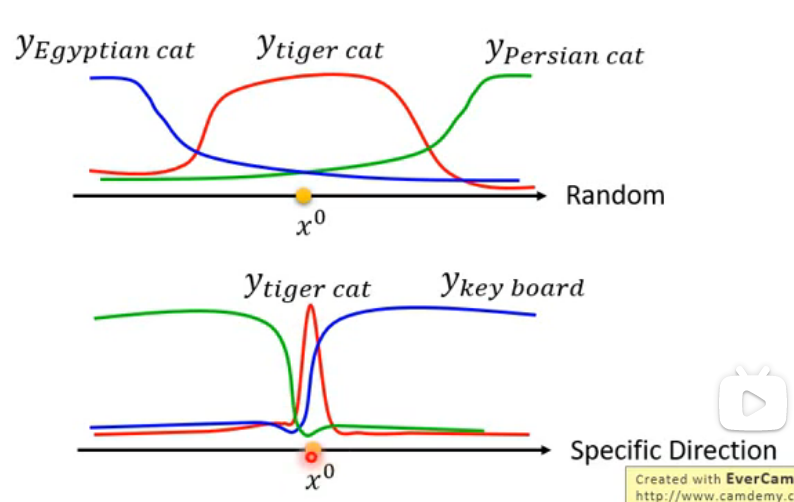
因为在不同方向上,模型对分类判断的灵敏阈值不同,在大部分方向上,判断为 的概率在 周围很大范围内都很高;但是在极个别方向上,模型在 附近的容忍阈值很小,微小的变化都会带来很大的不同,如下图所示:
攻击方法论文
FGSM (https://arxiv.org/abs/1412.6572)
Basic iterative method (https://arxiv.org/abs/1607.02533)
L-BFGS (https://arxiv.org/abs/1312.6199)
Deepfool (https://arxiv.org/abs/1511.04599)
JSMA (https://arxiv.org/abs/1511.07528)
C&W (https://arxiv.org/abs/1608.04644)
Elastic net attack (https://arxiv.org/abs/1709.04114)
Spatially Transformed (https://arxiv.org/abs/1801.02612)
One Pixel Attack (https://arxiv.org/abs/1710.08864)
最简单的攻击方法 FGSM(Fast Gradient Sign Method)
核心是使用了梯度符号矩阵(向量) 用来更新迭代, 仅由 1 与 -1 组成$$x^* \leftarrow x^0 - \epsilon \Delta x$$ $$\Delta x = \left [ \begin{matrix} \text{sgn}(\partial L / \partial x_1) \newline \text{sgn}(\partial L / \partial x_2) \newline \text{sgn}(\partial L / \partial x_3) \newline \vdots \end{matrix} \right ]$$
黑盒白盒攻击
白盒攻击:已知网络模型参数
黑盒攻击:未知网络模型参数
攻击的迁移性 :两个输入输出相似的网络模型,如果一个输入能够攻击其中一个模型,那么往往也能攻击另一个模型
因此,可以通过一个黑盒网络的输入输出,训练出一个已知的白盒网络,对白盒网络进行攻击,然后迁移至黑盒
Universal Adversarial Attack
论文 (https://arxiv.org/abs/1610.08401) 发现了一个“通用”的噪声可以成功攻击许多模型和输入,这样也可以实现黑盒攻击。
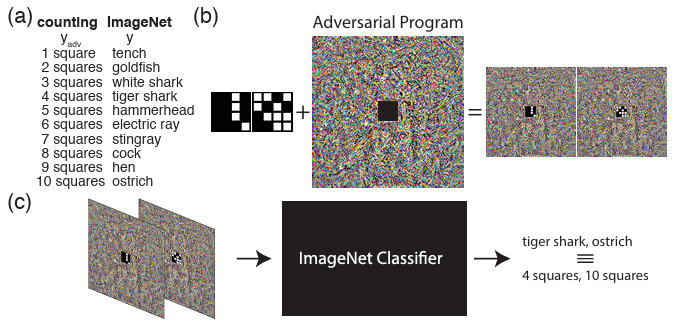
Adversarial Reprogramming
论文(https://arxiv.org/abs/1806.11146)发现了一个神奇的噪声padding,它可以攻击模型,改变模型的任务。原本模型执行的为分辨物品的任务,在输入添加了噪声padding的格子图像之后,模型便能够实现“数格子”的任务。
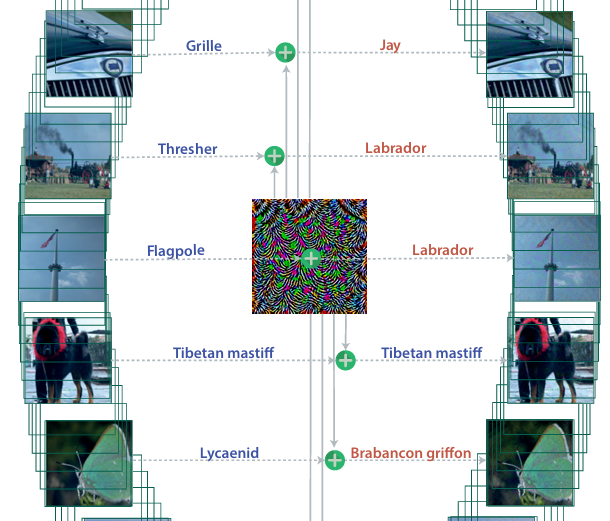
生活中的攻击
论文(https://arxiv.org/abs/1607.02533) 对生活中常见的图像进行攻击

防御
有两种类型的防御方法:
- 被动防御:不改变原本模型,在输入到网络前增加一些处理
- 例如在输入模型前加一个filter,进行一次平滑操作,可以滤除某些敏感方向的噪声
Feature Squeeze(https://arxiv.org/abs/1704.01155) 提出了一种判断攻击的方法,将图像经过两次不同 squeeze 后输入网络,分别计算输出与不经过 squeeze 操作的输出的差,根据 的最大值是否超过某个参数 来判定模型是否受到了攻击。 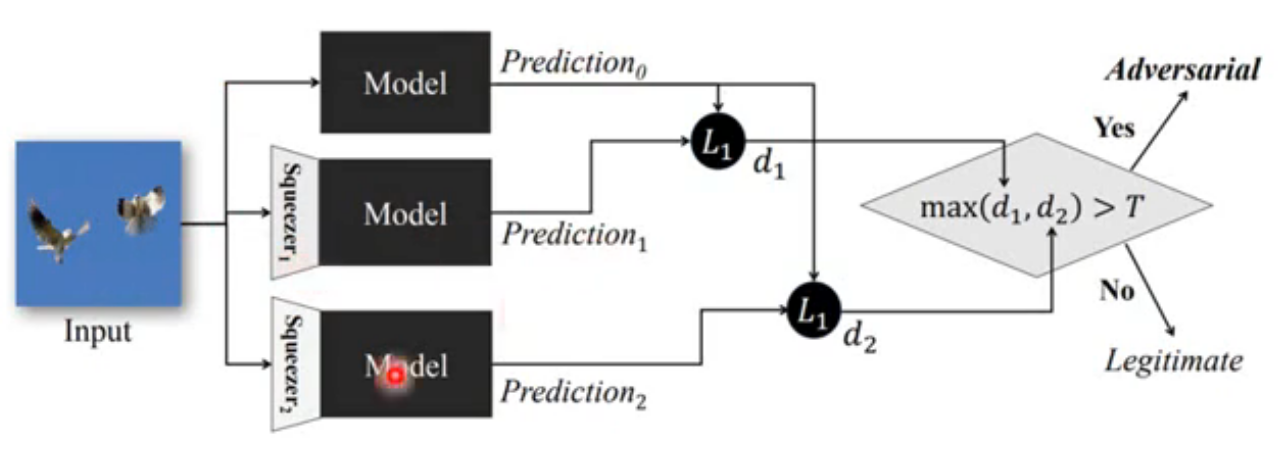
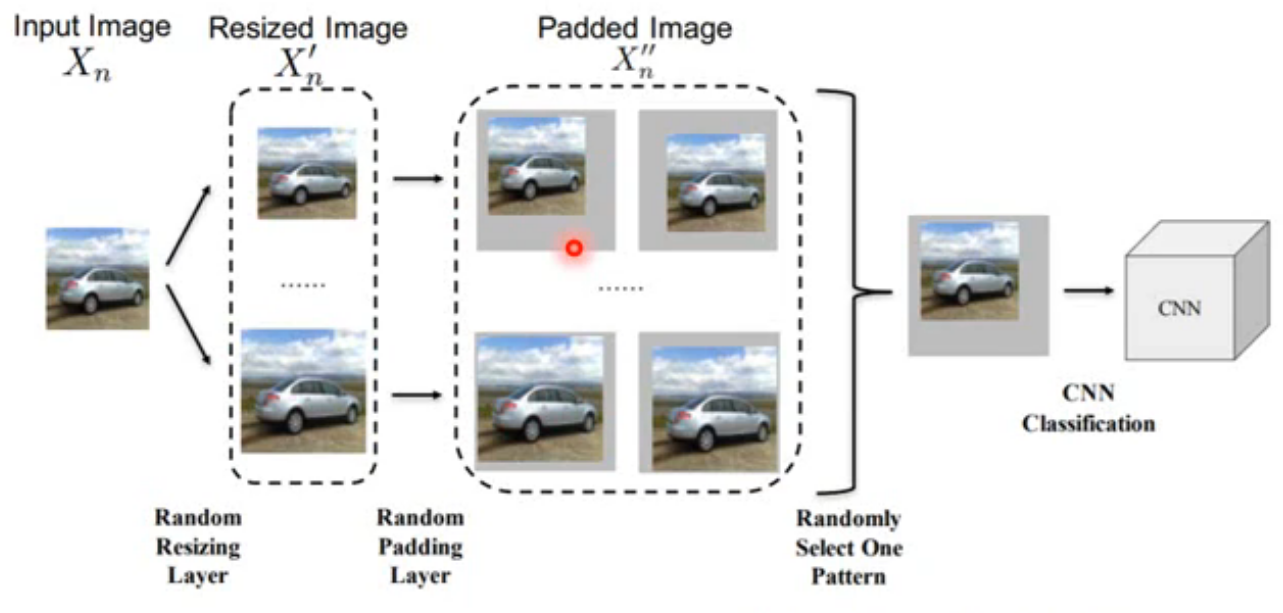
Randomization(https://arxiv.org/abs/1711.01991) 尝试在输入网络前对图像进行随机的 resize 和添加随机 padding 的操作防御攻击
- 主动防御:找出模型的漏洞并修补
- 用一组大小为 N 的训练数据集 训练模型
- 对于每一对训练数据 ,通过某种攻击算法( algorithm A )找到能够攻击模型的输入
- 将 组成新数据集 ,用 更新模型参数
- 将 2. 3. 重复若干遍(遍),避免修补模型后出现新的漏洞
这种方法只能防止 algorithm A 的攻击,若模型受到其它方法的攻击时,可能仍然无法防御
