(断更一年,失踪人口回归)
正在上信息论的课, 被香农老爷子对抽象事物的建模能力惊艳到了。在做实验的时候发现没啥好用的python库,就决定自己搓一个,趁着五一假期赶赶进度,链接附在末尾…
灵感摘录
信息论实验
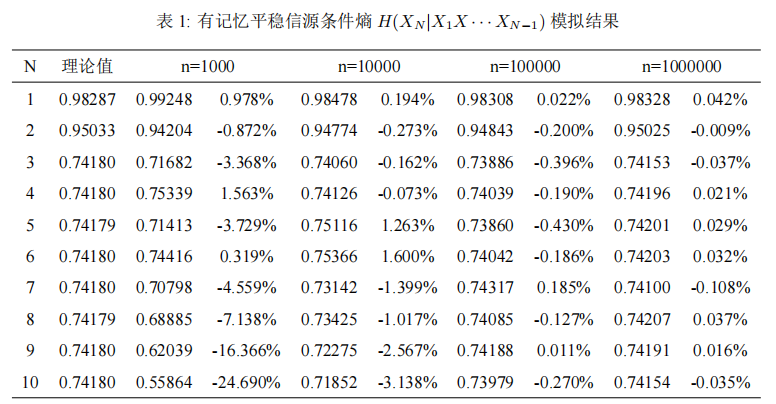
第一次信息论实验要搓二阶马尔可夫链,没看懂题目意思,题目说要模拟统计计算长度为 10 次扩展二阶马尔可夫信源的概率分布。
P(X1X2…X10)=[...]
我心想,哇擦,初始信源分布和转移矩阵都给出来了还能有啥猫腻呀,于是就哐哐哐搓了一个递归计算 m 阶马尔可夫链任意链长的概率分布的 python 脚本。搓的时候捣鼓了 numpy.ndarray 的 shape 好半天,总算搓出来了。结果一问同学,原来题目说的是统计计算概率分布,我给直接算了个理论值出来,后来索性就两个版本合成一个报告交上去了。

虽然多搓了一个递归函数,但我觉得这东西还挺有成就感的,心想着要不继续往后写算了…于是就又有了 pyShannon
高阶马尔可夫链的等效单步转移矩阵
2025.6.22 (信息论考试前一天):
樂,不听课的孩子有福了!本来以为是自己灵感乍现,原来这个东西在老师课上讲的例题里…
我把之前的递归函数改成了 MarkovChain.prob_topk() ,计算 k 长马尔可夫链 P(X1X2…Xk) 的概率分布,写库的时候小改小动还进展挺顺利
在实现 MarkovChain.prob_k() 计算离散链中任意 index 符号之间概率分布时候,这下犯难了。原始处理方法是,如果要计算下标 k=[1,3,7] 的概率分布 P(X1X3X7) ,就先调用 prob_topk(max(k)) ,然后沿着所有不需要的 axis 求和一下,但这也太 stupid 了,慢又占内存,怎么从 X1 直接跳到 X3,X7 呢?
C-K方程 告诉我们一阶马尔可夫链的单步转移矩阵通过乘方即可得到 k 步转移矩阵,那么更高阶应该也可以(可能之后会学到的吧)
一阶马尔可夫 k 步转移矩阵
设一个二元一阶马尔可夫链由 0,1 两种符号构成,给定初始分布 P1 和 单步转移矩阵 P2,2 即可从 $P_1 \rightarrow P_{1+k} $
P1=[P(X1=0)P(X1=1)], P1+k=([P(0∣0),P(1∣0)P(0∣1),P(1∣1)]k)T⋅P1=[P(X2=0)P(X2=1)]
或者从 $P_1 \rightarrow P_1P_2 $
P(X1X1+k)=[P(0∣0),P(1∣0)P(0∣1),P(1∣1)]k⊙[P1,P1]=[P(00),P(01)P(10),P(11)]
一阶马尔可夫链的情况很好理解,那 m 阶呢?
m 阶马尔可夫链的m步转移矩阵
m 阶马尔可夫链是否存在把一个矩阵乘方就可以走任意步的方法呢?答案一定是存在的。我们只知道二阶马尔可夫链的转移矩阵 P22,21(1) 这肯定不是我们要找的东西,因为它行列不等,根本不能乘方。那我们怎么找到它呢?
P22,21(1)=⎣⎢⎢⎢⎡P(0∣00),P(1∣00)P(0∣01),P(1∣01)P(0∣10),P(1∣10)P(0∣11),P(1∣11)⎦⎥⎥⎥⎤
首先观察一个 x 元一阶马尔可夫链的单步转移矩阵,它是 (x1,x1) 的,合理推测,如果 m 阶单步转移矩阵存在,那它一定是 (xm,xm) 的,如何找到它呢?
首先考虑一个四元一阶马尔可夫链, 它的单步转移矩阵 P41,41 可以表示为
P41,41(1)=⎣⎢⎢⎢⎡P(0∣0),P(1∣0),P(2∣0),P(3∣0)P(0∣1),P(1∣1),P(2∣1),P(3∣1)P(0∣2),P(1∣2),P(2∣2),P(3∣2)P(0∣3),P(1∣3),P(2∣3),P(3∣3)⎦⎥⎥⎥⎤
如果把符号 0,1,2,3 转为二元马尔可夫链的符号扩展,那么它的单步转移矩阵就是
P22,22(2)=⎣⎢⎢⎢⎡P(00∣00),P(01∣00),P(10∣00),P(11∣00)P(00∣01),P(01∣01),P(10∣01),P(11∣01)P(00∣10),P(01∣10),P(10∣10),P(11∣10)P(00∣11),P(01∣11),P(10∣11),P(11∣11)⎦⎥⎥⎥⎤
嚯喔哦,很快啊,这不就是二阶马尔可夫链的二步转移矩阵吗?咦!找到喽!因此我们找了 m 阶马尔可夫链的 m 步转移矩阵
m 阶马尔可夫链的等效单步转移矩阵
还是以二阶马尔可夫链的二步转移矩阵为例,假设就不让它跨两步,硬让它走一步,矩阵怎么改呢?
之前是
P(X3X4∣X1X2):X1X2X3X4→X1X2X3X4
走了两步,我要是非让它走一步呢?
P(X2X3∣X1X2):X1X2X3→X1X2X3
我们发现先验和后验符号中均出现了X2,我们还用矩阵的形式表示这种关系,并把相同的符号位置用下划线标出来,按道理来说,标下划线的X2处,一定会产生一样的符号对吧?
P22,22=⎣⎢⎢⎢⎡P(00∣00),P(01∣00),P(10∣00),P(11∣00)P(00∣01),P(01∣01),P(10∣01),P(11∣01)P(00∣10),P(01∣10),P(10∣10),P(11∣10)P(00∣11),P(01∣11),P(10∣11),P(11∣11)⎦⎥⎥⎥⎤
咦?竟然标下划线的符号不是一样的?这就很奇怪了,难道是我错了?emmm…按道理来说,这应该是个不可能事件,它的概率应该是0才对呀?
P22,22=⎣⎢⎢⎢⎡P(00∣00),0,P(00∣10),0,P(01∣00),0,P(01∣10),0,0,P(10∣01),0,P(10∣11),0P(11∣01)0P(11∣11)⎦⎥⎥⎥⎤
哎,这才对嘛!既然如此,那我们把后验符号中的X2去掉,只剩下先验中的X2,这样不是更清爽吗?
P22,22(1)=⎣⎢⎢⎢⎡P(0∣00),0,P(0∣10),0,P(1∣00),0,P(1∣10),0,0,P(0∣01),0,P(0∣11),0P(1∣01)0P(1∣11)⎦⎥⎥⎥⎤
对喽,这就是二阶马尔可夫链的等效单步转移矩阵 P22,22(1),满足形状 (x2,x2),而且它的每一行的和都为1,符合概率分布的定义,而且每一个非零元素,都可以在 P22,21(1) 中得到。
其实不难发现,P22,22(1) 的平方,正好是 P22,22(2),可以任意推广
因此,我们发现了一个 m 阶马尔可夫链的等效单步转移矩阵 Pxm,xm(1)
Pxm,xm(1)=⎣⎢⎢⎢⎢⎡P(0∣00…0),P(1∣00…0),…,P(x−1∣00…0)P(0∣00…1),P(1∣00…1),…,P(x−1∣00…1)⋮P(0∣11…1),P(1∣11…1),…,P(x−1∣11…1)⎦⎥⎥⎥⎥⎤
k
因此,我们可以便可以用 Pxm,xm(k) 计算符号跨越任意k步的马尔可夫链的概率分布了
通过参数选择继承的父类
在实现离散链类的文件中 chain.py ,虽然无记忆序列可以视为特殊的一阶马尔可夫链,但我觉得还是分开来实现比较好,毕竟用马尔可夫的方法计算无记忆序列的概率分布太慢了。因此我实现了两个链类 MarkovChain 和 MemorylessChain,都有类似的方法函数比如 prob_k() 和 prob_topk()。但在实现信源类的时候,需要继承链类的属性和方法,但无记忆和马尔可夫链序列又是分为两个类实现的,我又不想写两个信源类分别继承,我希望在实例化的时候可以动态选择继承哪个父类。结合ChatGPT,实现了如下方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| class Source():
def __new__(cls, P_trans, x=2, m=0, source_type='MemoryLess'):
attr = dict(cls.__dict__)
del attr['__new__']
if source_type == 'MemoryLess':
new_cls = type('MemoryLessSource', (MemoryLessChain,), attr)
elif source_type == 'Markov':
new_cls = type('MarkovSource', (MarkovChain,), attr)
else:
raise ValueError("Invalid source_type. Must be 'MemoryLess' or 'MarkovChain'.")
instance = new_cls(P_trans, x, m)
return instance
def __init__(self, P_trans, x, m):
super(self.__class__, self).__init__(P_trans, x, m)
print(f"ChildClass initialized with parameter")
|
在信源类Source的__new__方法中,动态选择父类,并创造类对象,用新创建的类对象实例化信源对象,并将Source类中除了新重写的__new__外的所有属性給新类,然后创建返回实例。在实际使用时,直接实例化Source类时传入参数source_type,就可以选择继承的父类了。
pyShannon使用说明
库还在写,先别急,等我啥时候把信道写完了再说…