学习记录:零阶优化——随机坐标下降,query-based 黑盒攻击
摘要
作者提出了一种基于查询的黑盒攻击方法 ZOO,该方法基于 C&W 方法的目标函数,且只需要访问到模型的输入( images ) 和输出 ( confidence )即可根据零阶随机坐标下降的方法进行目标函数的最小化,最终得到对抗样本,实现对模型的攻击。
理想的 ZOO 方法比较耗时,因此作者也针对性地提出了三条优化思路:
- attack-space dimension reduction
- hierarchical attack
- importance sampling
经过作者在 MNIST、CIFAR10 和 ImageNet 数据集上的测试,在攻击效果上,ZOO 方法达到了与 C&W Attack(白盒SOTA)相近的水平,并且远超基于替代模型的黑盒攻击模型。
一、介绍
ZOO 收益与挑战
Zero-order 是一种 derivative-free 的优化方法,只在优化过程中使用 在任意点的函数值。通过计算目标函数在两个相近点的函数值,就可以估计出函数在特定点 沿特定方向 的导数值$$ g_{x_v} : \frac{f(\boldsymbol{x}+h\boldsymbol{v})-f(\boldsymbol{x}-h\boldsymbol{v})}{2h} $$其中 应尽可能小。
这样,经典的优化算法例如梯度下降、坐标下降就可以使用这个估计出来的梯度来优化模型参数。
作者提出的 ZOO attack 利用了这一点开发出了一个黑盒攻击方法,且不需要替代模型。不过,ZOO 在应用上还有着较大的问题。
如果使用梯度下降法来优化模型参数,那么对于较大图像 ,输入将有 的维度,如果通过估计来求整个输入的梯度,那么需要在 个维度的所有 个方向进行估计,每次估计需要对模型进行两次查询,因此仅一次迭代就需要对模型进行 次访问,这是非常不切实际的。
因此作者采用坐标下降的方法来迭代地优化每一个坐标,这样便可以加速攻击。类似于在大数据集上对DNN模型进行训练(通常训练时仅求一个batch的梯度),作者并不打算在所有坐标点进行坐标下降,而是在一些小的 batch 上训练。这便需要探索一个有效的策略来设计一个采样方法,去优化一些重要的像素点。
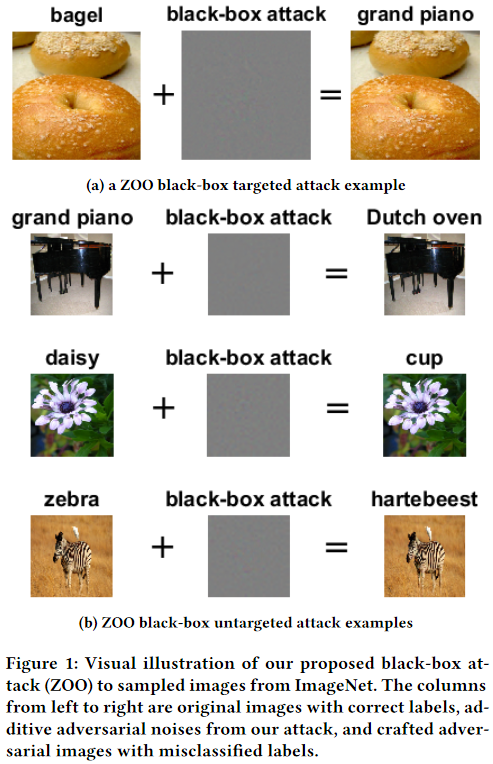
作者贡献
- 提出了在攻击成功率上比肩 C&W 的黑盒攻击算法 ZOO
- 提出了三种加速 ZOO ,提高其可行性的方法(attack-space dimension reduction, hierarchical attacks and importance sampling)
- 展示了 ZOO 对一个大型DNN(在ImageNet上训练的Inception-v3)模型的适用性(基于替代模型的黑盒攻击进能在训练于MNIST的小型网络上成功,很难拓展到大型网络)
二、相关工作
作者基于 C&W 攻击方法提出了 ZOO,并且进行了对比实验,效果优秀。可以解释为继承了C&W的有效性,或者因为攻击不采用替代模型而避免了迁移损失。
三、ZOO 方法及优化
logit layer representation(logits)
Logit layer representation(对数几率层表示)是深度学习中的一个术语,通常用于分类任务的神经网络模型。在神经网络中,logit layer 通常是指在最后一个隐藏层之后的一层,用于将隐藏层的输出转换为原始的预测值,这个预测值通常被称为 logits。
在分类任务中,logit通常指代模型对每个类别的预测得分,而这些得分通常会通过softmax函数进行归一化,以计算每个类别的概率。具体来说,logit layer 的输出是原始的预测值,尚未经过softmax函数转换。
假设对于一个已知模型,模型最终输出的结果 ,假设 logit layer 输出的结果为 ,则有 。那么在已知模型输出的情况下可以通过输出和 softmax 的反函数(也就是 函数)来反推 logit 函数的输出结果。
logit 的名字从哪来?
logits 这个名字来自最简单的二分类 logistic regression,在 logistic regression 的最后一般会使用 sigmoid 函数对原始输出进行归一化,得到所谓的“概率”,而 logit 函数 ( ) 是 sigmoid 函数的反函数,“概率” 通过 logit 函数即可得到 logistic regression 的原始输出,这个过程与上述提到的模型通过最终输出和 softmax 的反函数反推 the-layer-after-the-last-hidden-layer 的输出的过程类似。因此,在机器学习中,the-layer-after-the-last-hidden-layer 被成为 “logit layer”。
机器学习多分类任务一般使用的是 softmax 函数,而不是 sigmoid 函数。
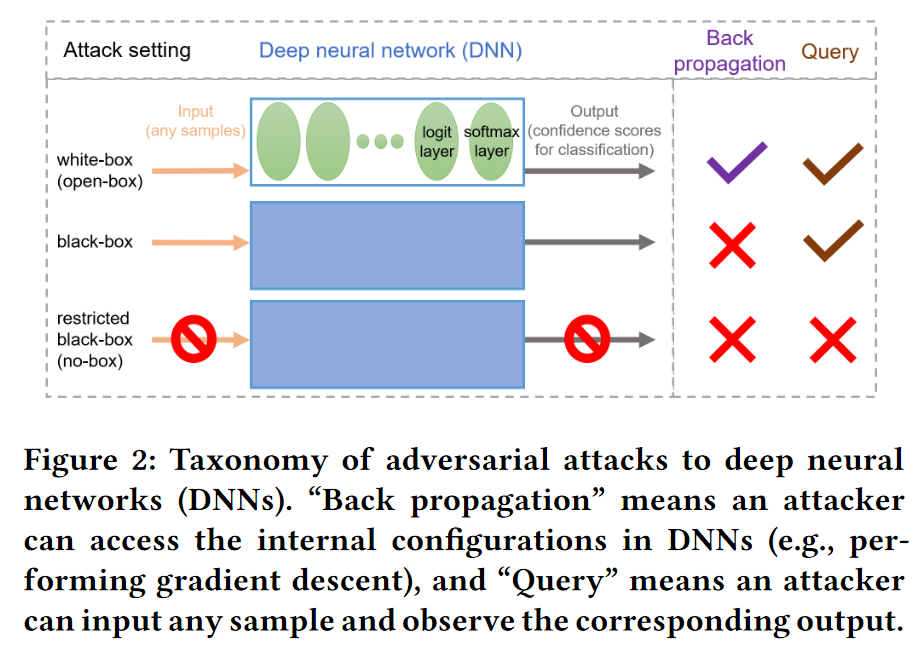
这是论文里用来说明不同种类攻击方法原理的结构图,这里比较清晰的表明了logit layer 和 softmax 的关系,所以放到这里来说明一下。
C&W方法
ZOO 方法受C&W方法表达式的启发,C&W方法可表示为:
\begin{align*} &\text{minimize}_x~~ \lVert \boldsymbol{x}-\boldsymbol{x_0} \rVert_2^2 + c \cdot f(\boldsymbol{x},t) \\ & \text{subject to }\boldsymbol{x}\in[0,1]^p \end{align*}
其中 为对抗样本, 为某个训练样本, 是正则化参数, 是 target-attack 的标签。 目标函数第一项衡量对抗样本与真实样本的差距,第二项则为 loss 函数。
在 C&W 中, 为
其中 是DNN中的 logit layer representation (logits),因此 与 被分类为 的概率相关, 是一个用于迁移性的可调的参数。C&W 的作者攻击特定DNN时将 设为 0,而在迁移攻击时建议设置更大的 。 可以看作是停止训练对抗样本的阈值 ,当 时目标函数的恒为 ,之后便无法优化 本身。 越大代表对抗样本被分类为 的概率越大。而在直接攻击DNN时, 仅需略微大于 即可认为是成功攻击;而在迁移训练时, 需要足够大以抵消迁移损失。
ZOO方法
C&W 方法是白盒攻击模型,因此可以进行反向传播并且能够知晓 logit layer 的信息,而黑盒模型不可以,因此作者针对这两点进行了改进:
- 使用零阶优化方法近似估计梯度信息
- 改进 loss 函数,直接使用模型输出 替代
修改 Loss 函数
没有模型的内部信息,就无法通过归一化的结果得到原始的输出,于是作者将 部分直接使用 代替(其实 刚好就是 softmax 的反函数),得到如下的 loss 函数:
对于 target-attack:
对于 untargeted-attack:
其中 是原始的图像标签。
零阶优化
stochastic gradient descent 和 batch gradient descent 广泛用于DNN模型的训练。不过对于黑盒模型,无法通过 back-propagation 获得模型的梯度信息,而通过零阶优化方法又要消耗大量的资源。为了解决这个问题,作者提出了以下的随机坐标下降方法,一次迭代仅需要两次函数估算。

这其中最重要的便是第三步对坐标的更新方法,对此作者有两种不同的尝试,分别是 ADAM 方法和牛顿方法,二者的算法分别为:
ADAM 方法:

牛顿方法:

在后续的实验中,作者发现 ADAM 法表现更优。
Attack-space dimension reduction
对于噪声 ,作者要攻击的维度过高,因此作者提出了一种减少攻击维度的方法,使用一种 变换函数 代替 。变换函数满足 $\boldsymbol{y}\in\mathbb{R}^m(m \lt p )~~ D(\boldsymbol{y})\in\mathbb{R}^p $ ,可以是线性或非线性的(例如双线性插值算法、离散余弦变换)。
使用变换函数的目标函数版本为:
\begin{align*} &\text{minimize}_x~~ \lVert D(\boldsymbol{y}) \rVert_2^2 + c \cdot f(\boldsymbol{x}_0 + D(\boldsymbol{y}),t) \\ & \text{subject to }\boldsymbol{x}_0 + D(\boldsymbol{y})\in[0,1]^p \end{align*}
Hierarchical attack
对于大图像的攻击,如果 取值过大也会增加时间消耗。因此作者提出了分层攻击方法。采用递增维度 的变换函数组 来逐步增大 的维度。
例如。初始时先用 映射,当 loss 函数的变换不明显时,改变攻击维度 ,再使用 。
Optimize the important pixels first
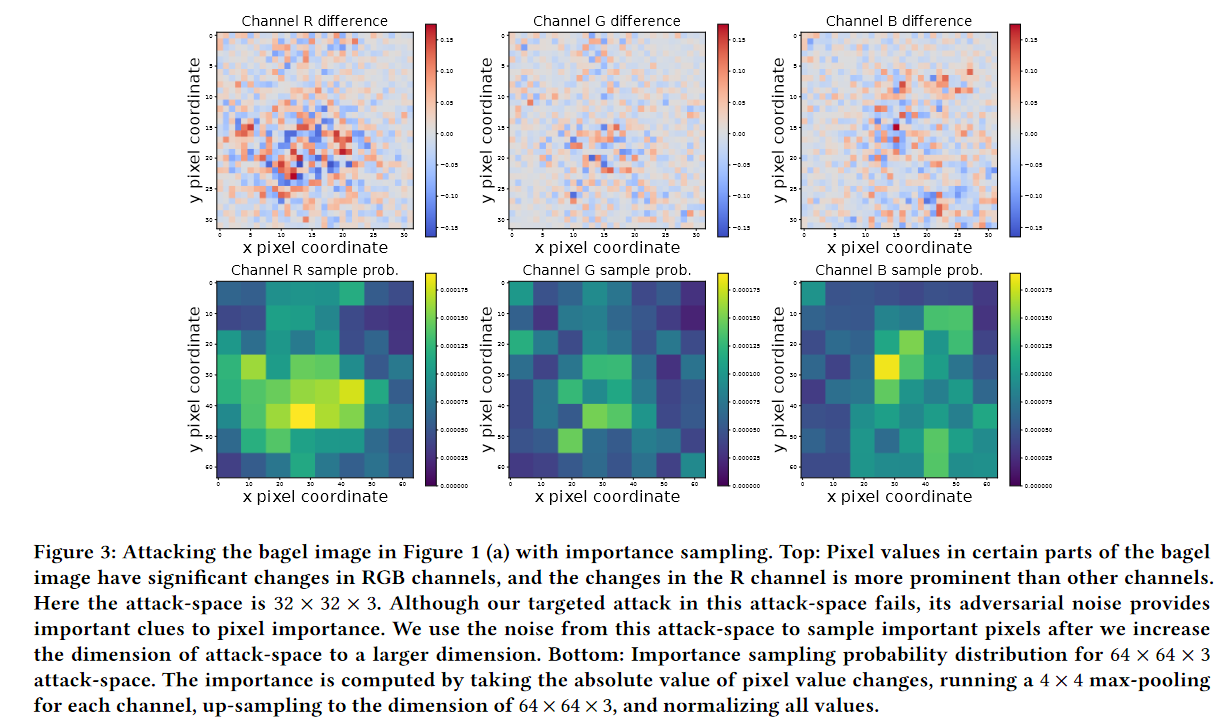
简而言之,就是找到一些对图像比较重要的像素进行攻击。例如,在图像边缘的点不是很重要,而在物体轮廓周围的图像便比较重要。作者通过比较每个区域中像素改变的绝对值来判断像素点的重要性,据此设定采样概率。
四、性能评价
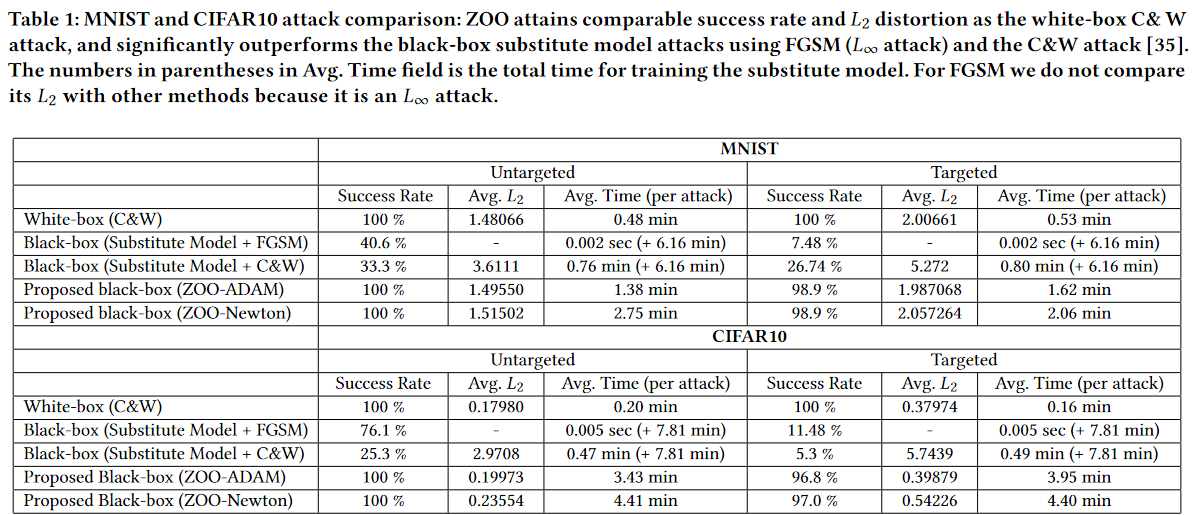
作者以ZOO模型进行对抗攻击,发现其结果近似于 C&W,并且性能远超基于替代模型的黑盒攻击。
MNIST and CIFAR10
对于所有模型,作者使用了 9 次二分法,来确定参数 的值。同时,由于MNIST 和 CIFER10数据集上图片较小,所有并没有使用上述三种优化方法。
训练 MNIST 时作者发现通过,在像素值接近 0 或 1 时,由于数值精度有限,通过 的变量代换会导致梯度消失。因此,作者在每次 MNIST 的更新后将像素值进行 box constraint 。而在CIFER10数据集上,作者发现使用变量代换会加快收敛,因为 CIFER10 数据集中大多数像素不太靠近边界。
攻击结果如图所示
Inception network with ImageNet
untargeted attack
攻击一个像 Inception-v3 的大型黑盒模型,通过替代模型的方法就不切实际了。
作者对数据集的图像进行了筛选,保证使用的图像大小至少为 的。作者仅使用 的攻击空间,切不使用分层攻击的方法,每次攻击进行 1500 个 iteration ,每次跌倒都要花费大概 20 分钟。
untargeted attack结果如下

targeted attack
作者在 untarget attack 中选择了一张攻击失败的图像数据,Inception-v3 将它分类为 “bagel” 并且有着 93% 的置信率,其它 top5 的分类决策分别为 “guillotine”-1.15%,“pretzel”-0.07%,“Granny Smith”-0.06% 和 “dough”-0.01%。作者故意选择了 “grand piano” 类作为 targeted attack 攻击标签,它有着 0.0006% 的置信率。
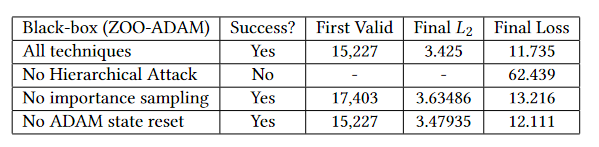
作者使用了分层攻击,用ADAM算法攻击总共20000个iteration,攻击空间从 到 ,分别在iteration=2000 和 10000 时上升,在攻击空间超过 后使用importance sampling 。
作者在攻击过程中发现了一个小 trick —— 在第一个有效攻击被发现后,重置ADAM solver的状态。原因如下:loss 函数有两部分 、 。当 $l_1 = 0 $ 时,对抗样本已经产生,优化器应该会尽量减小 以使对抗样本与原始图像尽可能接近。但是作者在实际训练时发现,即使 已经到达了 0 ,优化器仍然在让 提高。作者认为这是因为ADAM中存储的历史梯度数据过于陈旧,仅需要在 到达 0 后第一时间重置ADAM的状态即可。
过于陈旧可能是因为,每次迭代都只更新了极小一部分坐标的梯度,再加上 importance sampling 降低的采样的随机性,这就会造成整张图片不同像素坐标最近一次更新梯度的时间差异较大,某些久久未被更新的像素的梯度信息就会显得“陈旧”。
结果如下图所示:
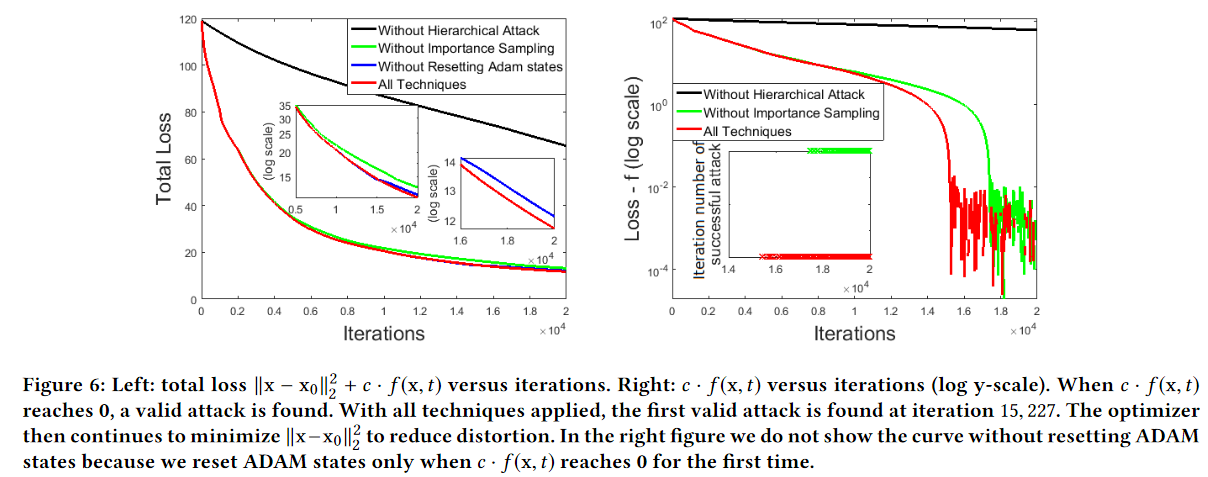
结果表明了分层攻击的方法对加快攻击速度起着极其重要的作用。importance sampling 在 iteration 超过 10000 后(attack-space 到达 )也起到了一定的效果。
重置 ADAM 的作用如下标所示